Run this notebook online:![]() or Colab:
or Colab: ![]()
7.5. Batch Normalization¶
Training deep neural nets is difficult. And getting them to converge in a reasonable amount of time can be tricky. In this section, we describe batch normalization (BN) [Ioffe & Szegedy, 2015], a popular and effective technique that consistently accelerates the convergence of deep nets. Together with residual blocks—covered in Section 7.6—BN has made it possible for practitioners to routinely train networks with over 100 layers.
7.5.1. Training Deep Networks¶
To motivate batch normalization, let us review a few practical challenges that arise when training ML models and neural nets in particular.
Choices regarding data preprocessing often make an enormous difference in the final results. Recall our application of multilayer perceptrons to predicting house prices (
sec_kaggle_house). Our first step when working with real data was to standardize our input features to each have a mean of zero and variance of one. Intuitively, this standardization plays nicely with our optimizers because it puts the parameters a-priori at a similar scale.For a typical MLP or CNN, as we train, the activations in intermediate layers may take values with widely varying magnitudes—both along the layers from the input to the output, across nodes in the same layer, and over time due to our updates to the model’s parameters. The inventors of batch normalization postulated informally that this drift in the distribution of activations could hamper the convergence of the network. Intuitively, we might conjecture that if one layer has activation values that are 100x that of another layer, this might necessitate compensatory adjustments in the learning rates.
Deeper networks are complex and easily capable of overfitting. This means that regularization becomes more critical.
Batch normalization is applied to individual layers (optionally, to all of them) and works as follows: In each training iteration, we first normalize the inputs (of batch normalization) by subtracting their mean and dividing by their standard deviation, where both are estimated based on the statistics of the current minibatch. Next, we apply a scaling coefficient and a scaling offset. It is precisely due to this normalization based on batch statistics that batch normalization derives its name.
Note that if we tried to apply BN with minibatches of size \(1\), we would not be able to learn anything. That is because after subtracting the means, each hidden node would take value \(0\)! As you might guess, since we are devoting a whole section to BN, with large enough minibatches, the approach proves effective and stable. One takeaway here is that when applying BN, the choice of minibatch size may be even more significant than without BN.
Formally, BN transforms the activations at a given layer \(\mathbf{x}\) according to the following expression:
Here, \(\hat{\mathbf{\mu}}\) is the minibatch sample mean and \(\hat{\mathbf{\sigma}}\) is the minibatch sample standard deviation. After applying BN, the resulting minibatch of activations has zero mean and unit variance. Because the choice of unit variance (vs some other magic number) is an arbitrary choice, we commonly include coordinate-wise scaling coefficients \(\mathbf{\gamma}\) and offsets \(\mathbf{\beta}\). Consequently, the activation magnitudes for intermediate layers cannot diverge during training because BN actively centers and rescales them back to a given mean and size (via \(\mathbf{\mu}\) and \(\sigma\)). One piece of practitioner’s intuition/wisdom is that BN seems to allows for more aggressive learning rates.
Formally, denoting a particular minibatch by \(\mathcal{B}\), we calculate \(\hat{\mathbf{\mu}}_\mathcal{B}\) and \(\hat\sigma_\mathcal{B}\) as follows:
Note that we add a small constant \(\epsilon > 0\) to the variance estimate to ensure that we never attempt division by zero, even in cases where the empirical variance estimate might vanish. The estimates \(\hat{\mathbf{\mu}}_\mathcal{B}\) and \(\hat{\mathbf{\sigma}}_\mathcal{B}\) counteract the scaling issue by using noisy estimates of mean and variance. You might think that this noisiness should be a problem. As it turns out, this is actually beneficial.
This turns out to be a recurring theme in deep learning. For reasons that are not yet well-characterized theoretically, various sources of noise in optimization often lead to faster training and less overfitting. While traditional machine learning theorists might buckle at this characterization, this variation appears to act as a form of regularization. In some preliminary research, [Teye et al., 2018] and [Luo et al., 2018] relate the properties of BN to Bayesian Priors and penalties respectively. In particular, this sheds some light on the puzzle of why BN works best for moderate minibatches sizes in the \(50\)–\(100\) range.
Fixing a trained model, you might (rightly) think that we would prefer to use the entire dataset to estimate the mean and variance. Once training is complete, why would we want the same image to be classified differently, depending on the batch in which it happens to reside? During training, such exact calculation is infeasible because the activations for all data points change every time we update our model. However, once the model is trained, we can calculate the means and variances of each layer’s activations based on the entire dataset. Indeed this is standard practice for models employing batch normalization and thus BN layers function differently in training mode (normalizing by minibatch statistics) and in prediction mode (normalizing by dataset statistics).
We are now ready to take a look at how batch normalization works in practice.
7.5.2. Batch Normalization Layers¶
Batch normalization implementations for fully-connected layers and convolutional layers are slightly different. We discuss both cases below. Recall that one key differences between BN and other layers is that because BN operates on a full minibatch at a time, we cannot just ignore the batch dimension as we did before when introducing other layers.
7.5.2.1. Fully-Connected Layers¶
When applying BN to fully-connected layers, we usually insert BN after the affine transformation and before the nonlinear activation function. Denoting the input to the layer by \(\mathbf{x}\), the linear transform (with weights \(\theta\)) by \(f_{\theta}(\cdot)\), the activation function by \(\phi(\cdot)\), and the BN operation with parameters \(\mathbf{\beta}\) and \(\mathbf{\gamma}\) by \(\mathrm{BN}_{\mathbf{\beta}, \mathbf{\gamma}}\), we can express the computation of a BN-enabled, fully-connected layer \(\mathbf{h}\) as follows:
Recall that mean and variance are computed on the same minibatch \(\mathcal{B}\) on which the transformation is applied. Also recall that the scaling coefficient \(\mathbf{\gamma}\) and the offset \(\mathbf{\beta}\) are parameters that need to be learned jointly with the more familiar parameters \(\mathbf{\theta}\).
7.5.2.2. Convolutional Layers¶
Similarly, with convolutional layers, we typically apply BN after the convolution and before the nonlinear activation function. When the convolution has multiple output channels, we need to carry out batch normalization for each of the outputs of these channels, and each channel has its own scale and shift parameters, both of which are scalars. Assume that our minibatches contain \(m\) each and that for each channel, the output of the convolution has height \(p\) and width \(q\). For convolutional layers, we carry out each batch normalization over the \(m \cdot p \cdot q\) elements per output channel simultaneously. Thus we collect the values over all spatial locations when computing the mean and variance and consequently (within a given channel) apply the same \(\hat{\mathbf{\mu}}\) and \(\hat{\mathbf{\sigma}}\) to normalize the values at each spatial location.
7.5.2.3. Batch Normalization During Prediction¶
As we mentioned earlier, BN typically behaves differently in training mode and prediction mode. First, the noise in \(\mathbf{\mu}\) and \(\mathbf{\sigma}\) arising from estimating each on minibatches are no longer desirable once we have trained the model. Second, we might not have the luxury of computing per-batch normalization statistics, e.g., we might need to apply our model to make one prediction at a time.
Typically, after training, we use the entire dataset to compute stable estimates of the activation statistics and then fix them at prediction time. Consequently, BN behaves differently during training and at test time. Recall that dropout also exhibits this characteristic.
7.5.3. Implementation from Scratch¶
Below, firstly we get all the relevant libraries needed to implement BatchNorm. After that, we implement a batch normalization layer with NDArrays from scratch:
%load ../utils/djl-imports
%load ../utils/plot-utils
%load ../utils/Training.java
%load ../utils/Accumulator.java
import ai.djl.basicdataset.cv.classification.*;
import org.apache.commons.lang3.ArrayUtils;
public NDList batchNormUpdate(NDArray X, NDArray gamma,
NDArray beta, NDArray movingMean, NDArray movingVar,
float eps, float momentum, boolean isTraining) {
// attach moving mean and var to submanager to close intermediate computation values
// at the end to avoid memory leak
try(NDManager subManager = movingMean.getManager().newSubManager()){
movingMean.attach(subManager);
movingVar.attach(subManager);
NDArray xHat;
NDArray mean;
NDArray var;
if (!isTraining) {
// If it is the prediction mode, directly use the mean and variance
// obtained from the incoming moving average
xHat = X.sub(movingMean).div(movingVar.add(eps).sqrt());
} else {
if (X.getShape().dimension() == 2) {
// When using a fully connected layer, calculate the mean and
// variance on the feature dimension
mean = X.mean(new int[]{0}, true);
var = X.sub(mean).pow(2).mean(new int[]{0}, true);
} else {
// When using a two-dimensional convolutional layer, calculate the
// mean and variance on the channel dimension (axis=1). Here we
// need to maintain the shape of `X`, so that the broadcast
// operation can be carried out later
mean = X.mean(new int[]{0, 2, 3}, true);
var = X.sub(mean).pow(2).mean(new int[]{0, 2, 3}, true);
}
// In training mode, the current mean and variance are used for the
// standardization
xHat = X.sub(mean).div(var.add(eps).sqrt());
// Update the mean and variance of the moving average
movingMean = movingMean.mul(momentum).add(mean.mul(1.0f - momentum));
movingVar = movingVar.mul(momentum).add(var.mul(1.0f - momentum));
}
NDArray Y = xHat.mul(gamma).add(beta); // Scale and shift
// attach moving mean and var back to original manager to keep their values
movingMean.attach(subManager.getParentManager());
movingVar.attach(subManager.getParentManager());
return new NDList(Y, movingMean, movingVar);
}
}
We can now create a proper BatchNorm layer. Our layer will maintain
proper parameters corresponding for scale gamma and shift beta, both of
which will be updated in the course of training. Additionally, our layer
will maintain a moving average of the means and variances for subsequent
use during model prediction. The numFeatures parameter required by the
BatchNorm instance is the number of outputs for a fully-connected layer
and the number of output channels for a convolutional layer. The
numDimensions parameter also required by this instance is 2 for a
fully-connected layer and 4 for a convolutional layer.
Putting aside the algorithmic details, note the design pattern
underlying our implementation of the layer. Typically, we define the
math in a separate function, say batchNormUpdate. We then integrate
this functionality into a custom layer, whose code mostly addresses
bookkeeping matters, such as moving data to the right device context,
allocating and initializing any required variables, keeping track of
running averages (here for mean and variance), etc. This pattern enables
a clean separation of math from boilerplate code. Also note that for the
sake of convenience we did not worry about automatically inferring the
input shape here, thus we need to specify the number of features
throughout. Do not worry, the DJL BatchNorm layer will care of this
for us.
public class BatchNormBlock extends AbstractBlock {
private NDArray movingMean;
private NDArray movingVar;
private Parameter gamma;
private Parameter beta;
private Shape shape;
// num_features: the number of outputs for a fully-connected layer
// or the number of output channels for a convolutional layer.
// num_dims: 2 for a fully-connected layer and 4 for a convolutional layer.
public BatchNormBlock(int numFeatures, int numDimensions) {
if (numDimensions == 2) {
shape = new Shape(1, numFeatures);
} else {
shape = new Shape(1, numFeatures, 1, 1);
}
// The scale parameter and the shift parameter involved in gradient
// finding and iteration are initialized to 0 and 1 respectively
gamma = addParameter(
Parameter.builder()
.setName("gamma")
.setType(Parameter.Type.GAMMA)
.optShape(shape)
.build());
beta = addParameter(
Parameter.builder()
.setName("beta")
.setType(Parameter.Type.BETA)
.optShape(shape)
.build());
// All the variables not involved in gradient finding and iteration are
// initialized to 0. Create a base manager to maintain their values
// throughout the entire training process
NDManager manager = NDManager.newBaseManager();
movingMean = manager.zeros(shape);
movingVar = manager.zeros(shape);
}
@Override
public String toString() {
return "BatchNormBlock()";
}
@Override
protected NDList forwardInternal(
ParameterStore parameterStore,
NDList inputs,
boolean training,
PairList<String, Object> params) {
NDList result = batchNormUpdate(inputs.singletonOrThrow(),
gamma.getArray(), beta.getArray(), this.movingMean, this.movingVar, 1e-12f, 0.9f, training);
// close previous NDArray before assigning new values
if(training){
this.movingMean.close();
this.movingVar.close();
}
// Save the updated `movingMean` and `movingVar`
this.movingMean = result.get(1);
this.movingVar = result.get(2);
return new NDList(result.get(0));
}
@Override
public Shape[] getOutputShapes(Shape[] inputs) {
Shape[] current = inputs;
for (Block block : children.values()) {
current = block.getOutputShapes(current);
}
return current;
}
}
7.5.4. Using a Batch Normalization LeNet¶
To see how to apply BatchNorm in context, below we apply it to a
traditional LeNet model (Section 6.6). Recall that BN is
typically applied after the convolutional layers and fully-connected
layers but before the corresponding activation functions.
SequentialBlock net = new SequentialBlock()
.add(
Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.setFilters(6).build())
.add(new BatchNormBlock(6, 4))
.add(Pool.maxPool2dBlock(new Shape(2, 2), new Shape(2, 2)))
.add(
Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.setFilters(16).build())
.add(new BatchNormBlock(16, 4))
.add(Activation::sigmoid)
.add(Pool.maxPool2dBlock(new Shape(2, 2), new Shape(2, 2)))
.add(Blocks.batchFlattenBlock())
.add(Linear.builder().setUnits(120).build())
.add(new BatchNormBlock(120, 2))
.add(Activation::sigmoid)
.add(Blocks.batchFlattenBlock())
.add(Linear.builder().setUnits(84).build())
.add(new BatchNormBlock(84, 2))
.add(Activation::sigmoid)
.add(Linear.builder().setUnits(10).build());
Let’s initialize the batchSize, numEpochs and the relevant arrays to store the data from the training function.
int batchSize = 256;
int numEpochs = Integer.getInteger("MAX_EPOCH", 10);
double[] trainLoss;
double[] testAccuracy;
double[] epochCount;
double[] trainAccuracy;
epochCount = new double[numEpochs];
for (int i = 0; i < epochCount.length; i++) {
epochCount[i] = i+1;
}
As before, we will train our network on the Fashion-MNIST dataset. This code is virtually identical to that when we first trained LeNet (Section 6.6). The main difference is the considerably larger learning rate.
FashionMnist trainIter = FashionMnist.builder()
.optUsage(Dataset.Usage.TRAIN)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
FashionMnist testIter = FashionMnist.builder()
.optUsage(Dataset.Usage.TEST)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
trainIter.prepare();
testIter.prepare();
float lr = 1.0f;
Loss loss = Loss.softmaxCrossEntropyLoss();
Tracker lrt = Tracker.fixed(lr);
Optimizer sgd = Optimizer.sgd().setLearningRateTracker(lrt).build();
DefaultTrainingConfig config = new DefaultTrainingConfig(loss)
.optOptimizer(sgd) // Optimizer (loss function)
.optDevices(Engine.getInstance().getDevices(1)) // single GPU
.addEvaluator(new Accuracy()) // Model Accuracy
.addTrainingListeners(TrainingListener.Defaults.logging()); // Logging
Model model = Model.newInstance("batch-norm");
model.setBlock(net);
Trainer trainer = model.newTrainer(config);
trainer.initialize(new Shape(1, 1, 28, 28));
Map<String, double[]> evaluatorMetrics = new HashMap<>();
double avgTrainTimePerEpoch = Training.trainingChapter6(trainIter, testIter, numEpochs, trainer, evaluatorMetrics);
INFO Training on: 1 GPUs.
INFO Load MXNet Engine Version 1.9.0 in 0.060 ms.
Training: 100% |████████████████████████████████████████| Accuracy: 0.78, SoftmaxCrossEntropyLoss: 0.62
Validating: 100% |████████████████████████████████████████|
INFO Epoch 1 finished.
INFO Train: Accuracy: 0.78, SoftmaxCrossEntropyLoss: 0.62
INFO Validate: Accuracy: 0.81, SoftmaxCrossEntropyLoss: 0.59
Training: 100% |████████████████████████████████████████| Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.39
Validating: 100% |████████████████████████████████████████|
INFO Epoch 2 finished.
INFO Train: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.39
INFO Validate: Accuracy: 0.79, SoftmaxCrossEntropyLoss: 0.60
Training: 100% |████████████████████████████████████████| Accuracy: 0.87, SoftmaxCrossEntropyLoss: 0.35
Validating: 100% |████████████████████████████████████████|
INFO Epoch 3 finished.
INFO Train: Accuracy: 0.87, SoftmaxCrossEntropyLoss: 0.35
INFO Validate: Accuracy: 0.78, SoftmaxCrossEntropyLoss: 0.64
Training: 100% |████████████████████████████████████████| Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.33
Validating: 100% |████████████████████████████████████████|
INFO Epoch 4 finished.
INFO Train: Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.33
INFO Validate: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.40
Training: 100% |████████████████████████████████████████| Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.31
Validating: 100% |████████████████████████████████████████|
INFO Epoch 5 finished.
INFO Train: Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.31
INFO Validate: Accuracy: 0.87, SoftmaxCrossEntropyLoss: 0.36
Training: 100% |████████████████████████████████████████| Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.29
Validating: 100% |████████████████████████████████████████|
INFO Epoch 6 finished.
INFO Train: Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.29
INFO Validate: Accuracy: 0.80, SoftmaxCrossEntropyLoss: 0.59
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.28
Validating: 100% |████████████████████████████████████████|
INFO Epoch 7 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.28
INFO Validate: Accuracy: 0.83, SoftmaxCrossEntropyLoss: 0.50
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.27
Validating: 100% |████████████████████████████████████████|
INFO Epoch 8 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.27
INFO Validate: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.39
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
Validating: 100% |████████████████████████████████████████|
INFO Epoch 9 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
INFO Validate: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.40
Training: 100% |████████████████████████████████████████| Accuracy: 0.91, SoftmaxCrossEntropyLoss: 0.25
Validating: 100% |████████████████████████████████████████|
INFO Epoch 10 finished.
INFO Train: Accuracy: 0.91, SoftmaxCrossEntropyLoss: 0.25
INFO Validate: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.38
trainLoss = evaluatorMetrics.get("train_epoch_SoftmaxCrossEntropyLoss");
trainAccuracy = evaluatorMetrics.get("train_epoch_Accuracy");
testAccuracy = evaluatorMetrics.get("validate_epoch_Accuracy");
System.out.printf("loss %.3f,", trainLoss[numEpochs - 1]);
System.out.printf(" train acc %.3f,", trainAccuracy[numEpochs - 1]);
System.out.printf(" test acc %.3f\n", testAccuracy[numEpochs - 1]);
System.out.printf("%.1f examples/sec", trainIter.size() / (avgTrainTimePerEpoch / Math.pow(10, 9)));
System.out.println();
loss 0.253, train acc 0.908, test acc 0.853
14286.4 examples/sec
Let us have a look at the scale parameter gamma and the shift
parameter beta learned from the first batch normalization layer.
// Printing the value of gamma and beta in the first BatchNorm layer.
List<Parameter> batchNormFirstParams = net.getChildren().values().get(1).getParameters().values();
System.out.println("gamma " + batchNormFirstParams.get(0).getArray().reshape(-1));
System.out.println("beta " + batchNormFirstParams.get(1).getArray().reshape(-1));
gamma ND: (6) gpu(0) float32
[1.2964, 1.3052, 1.1294, 1.6468, 1.4031, 0.9528]
beta ND: (6) gpu(0) float32
[-1.97340313e-07, -1.54651687e-08, -5.90235629e-08, 1.37331057e-07, -2.05921111e-07, 7.86741339e-10]
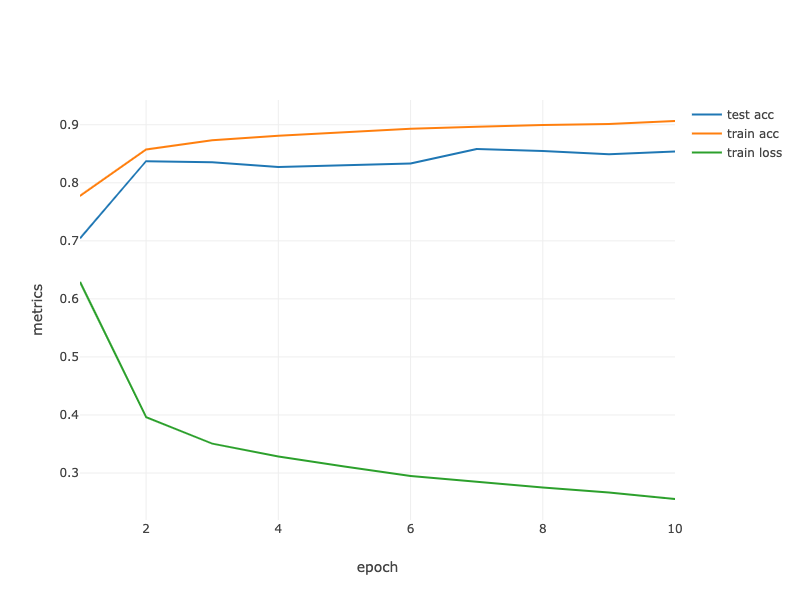
Fig. 7.5.1 Contour Gradient Descent.¶
String[] lossLabel = new String[trainLoss.length + testAccuracy.length + trainAccuracy.length];
Arrays.fill(lossLabel, 0, trainLoss.length, "train loss");
Arrays.fill(lossLabel, trainAccuracy.length, trainLoss.length + trainAccuracy.length, "train acc");
Arrays.fill(lossLabel, trainLoss.length + trainAccuracy.length,
trainLoss.length + testAccuracy.length + trainAccuracy.length, "test acc");
Table data = Table.create("Data").addColumns(
DoubleColumn.create("epoch", ArrayUtils.addAll(epochCount, ArrayUtils.addAll(epochCount, epochCount))),
DoubleColumn.create("metrics", ArrayUtils.addAll(trainLoss, ArrayUtils.addAll(trainAccuracy, testAccuracy))),
StringColumn.create("lossLabel", lossLabel)
);
render(LinePlot.create("", data, "epoch", "metrics", "lossLabel"),"text/html");
7.5.5. Concise Implementation¶
Compared with the BatchNorm class, which we just defined ourselves,
the BatchNorm class defined by nn module in DJL is easier to
use. In DJL, we do not have to worry about numFeatures or
numDimensions. Instead, these parameter values will be inferred
automatically via delayed initialization. Otherwise, the code looks
virtually identical to the application our implementation above.
SequentialBlock block = new SequentialBlock()
.add(
Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.setFilters(6).build())
.add(BatchNorm.builder().build())
.add(Pool.maxPool2dBlock(new Shape(2, 2), new Shape(2, 2)))
.add(
Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.setFilters(16).build())
.add(BatchNorm.builder().build())
.add(Activation::sigmoid)
.add(Pool.maxPool2dBlock(new Shape(2, 2), new Shape(2, 2)))
.add(Blocks.batchFlattenBlock())
.add(Linear.builder().setUnits(120).build())
.add(BatchNorm.builder().build())
.add(Activation::sigmoid)
.add(Blocks.batchFlattenBlock())
.add(Linear.builder().setUnits(84).build())
.add(BatchNorm.builder().build())
.add(Activation::sigmoid)
.add(Linear.builder().setUnits(10).build());
Below, we use the same hyperparameters to train out model. Note that as usual, the high-level API variant runs much faster because its code has been compiled to C++/CUDA while our custom implementation must be interpreted by Python.
Loss loss = Loss.softmaxCrossEntropyLoss();
Tracker lrt = Tracker.fixed(1.0f);
Optimizer sgd = Optimizer.sgd().setLearningRateTracker(lrt).build();
Model model = Model.newInstance("batch-norm");
model.setBlock(block);
DefaultTrainingConfig config = new DefaultTrainingConfig(loss)
.optOptimizer(sgd) // Optimizer (loss function)
.addEvaluator(new Accuracy()) // Model Accuracy
.addTrainingListeners(TrainingListener.Defaults.logging()); // Logging
Trainer trainer = model.newTrainer(config);
trainer.initialize(new Shape(1, 1, 28, 28));
Map<String, double[]> evaluatorMetrics = new HashMap<>();
double avgTrainTimePerEpoch = 0;
INFO Training on: 4 GPUs.
INFO Load MXNet Engine Version 1.9.0 in 0.021 ms.
avgTrainTimePerEpoch = Training.trainingChapter6(trainIter, testIter, numEpochs, trainer, evaluatorMetrics);
Training: 100% |████████████████████████████████████████| Accuracy: 0.75, SoftmaxCrossEntropyLoss: 0.99
Validating: 100% |████████████████████████████████████████|
INFO Epoch 1 finished.
INFO Train: Accuracy: 0.75, SoftmaxCrossEntropyLoss: 0.99
INFO Validate: Accuracy: 0.82, SoftmaxCrossEntropyLoss: 0.50
Training: 100% |████████████████████████████████████████| Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.42
Validating: 100% |████████████████████████████████████████|
INFO Epoch 2 finished.
INFO Train: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.42
INFO Validate: Accuracy: 0.83, SoftmaxCrossEntropyLoss: 0.48
Training: 100% |████████████████████████████████████████| Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.37
Validating: 100% |████████████████████████████████████████|
INFO Epoch 3 finished.
INFO Train: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.37
INFO Validate: Accuracy: 0.76, SoftmaxCrossEntropyLoss: 0.62
Training: 100% |████████████████████████████████████████| Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.33
Validating: 100% |████████████████████████████████████████|
INFO Epoch 4 finished.
INFO Train: Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.33
INFO Validate: Accuracy: 0.84, SoftmaxCrossEntropyLoss: 0.44
Training: 100% |████████████████████████████████████████| Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.31
Validating: 100% |████████████████████████████████████████|
INFO Epoch 5 finished.
INFO Train: Accuracy: 0.88, SoftmaxCrossEntropyLoss: 0.31
INFO Validate: Accuracy: 0.83, SoftmaxCrossEntropyLoss: 0.45
Training: 100% |████████████████████████████████████████| Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.30
Validating: 100% |████████████████████████████████████████|
INFO Epoch 6 finished.
INFO Train: Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.30
INFO Validate: Accuracy: 0.82, SoftmaxCrossEntropyLoss: 0.53
Training: 100% |████████████████████████████████████████| Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.29
Validating: 100% |████████████████████████████████████████|
INFO Epoch 7 finished.
INFO Train: Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.29
INFO Validate: Accuracy: 0.81, SoftmaxCrossEntropyLoss: 0.54
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.27
Validating: 100% |████████████████████████████████████████|
INFO Epoch 8 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.27
INFO Validate: Accuracy: 0.84, SoftmaxCrossEntropyLoss: 0.44
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
Validating: 100% |████████████████████████████████████████|
INFO Epoch 9 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
INFO Validate: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.40
Training: 100% |████████████████████████████████████████| Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
Validating: 100% |████████████████████████████████████████|
INFO Epoch 10 finished.
INFO Train: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.26
INFO Validate: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.42
trainLoss = evaluatorMetrics.get("train_epoch_SoftmaxCrossEntropyLoss");
trainAccuracy = evaluatorMetrics.get("train_epoch_Accuracy");
testAccuracy = evaluatorMetrics.get("validate_epoch_Accuracy");
System.out.printf("loss %.3f,", trainLoss[numEpochs - 1]);
System.out.printf(" train acc %.3f,", trainAccuracy[numEpochs - 1]);
System.out.printf(" test acc %.3f\n", testAccuracy[numEpochs - 1]);
System.out.printf("%.1f examples/sec", trainIter.size() / (avgTrainTimePerEpoch / Math.pow(10, 9)));
System.out.println();
loss 0.257, train acc 0.904, test acc 0.857
7422.2 examples/sec
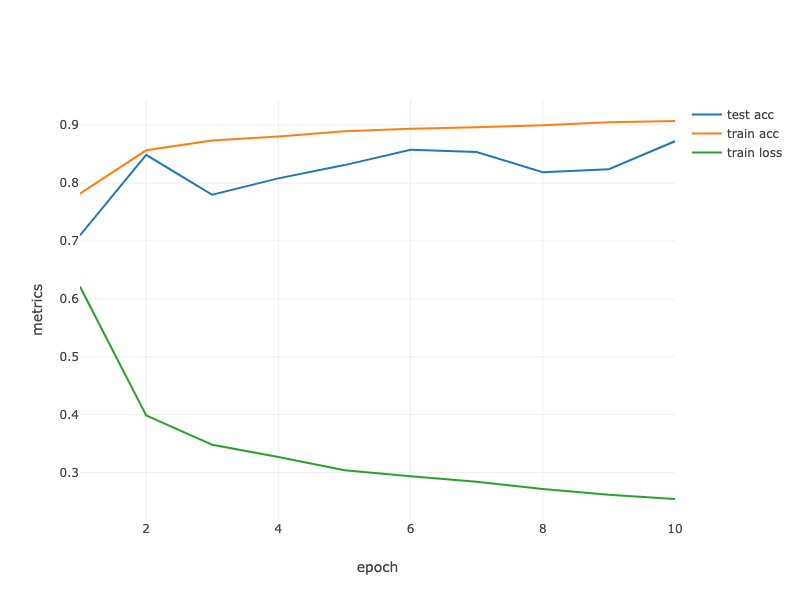
Fig. 7.5.2 Contour Gradient Descent.¶
String[] lossLabel = new String[trainLoss.length + testAccuracy.length + trainAccuracy.length];
Arrays.fill(lossLabel, 0, trainLoss.length, "train loss");
Arrays.fill(lossLabel, trainAccuracy.length, trainLoss.length + trainAccuracy.length, "train acc");
Arrays.fill(lossLabel, trainLoss.length + trainAccuracy.length,
trainLoss.length + testAccuracy.length + trainAccuracy.length, "test acc");
Table data = Table.create("Data").addColumns(
DoubleColumn.create("epoch", ArrayUtils.addAll(epochCount, ArrayUtils.addAll(epochCount, epochCount))),
DoubleColumn.create("metrics", ArrayUtils.addAll(trainLoss, ArrayUtils.addAll(trainAccuracy, testAccuracy))),
StringColumn.create("lossLabel", lossLabel)
);
render(LinePlot.create("", data, "epoch", "metrics", "lossLabel"),"text/html");
7.5.6. Controversy¶
Intuitively, batch normalization is thought to make the optimization landscape smoother. However, we must be careful to distinguish between speculative intuitions and true explanations for the phenomena that we observe when training deep models. Recall that we do not even know why simpler deep neural networks (MLPs and conventional CNNs) generalize well in the first place. Even with dropout and \(L_2\) regularization, they remain so flexible that their ability to generalize to unseen data cannot be explained via conventional learning-theoretic generalization guarantees.
In the original paper proposing batch normalization, the authors, in addition to introducing a powerful and useful tool, offered an explanation for why it works: by reducing internal covariate shift. Presumably by internal covariate shift the authors meant something like the intuition expressed above—the notion that the distribution of activations changes over the course of training. However there were two problems with this explanation: (1) This drift is very different from covariate shift, rendering the name a misnomer. (2) The explanation offers an under-specified intuition but leaves the question of why precisely this technique works an open question wanting for a rigorous explanation. Throughout this book, we aim to convey the intuitions that practitioners use to guide their development of deep neural networks. However, we believe that it is important to separate these guiding intuitions from established scientific fact. Eventually, when you master this material and start writing your own research papers you will want to be clear to delineate between technical claims and hunches.
Following the success of batch normalization, its explanation in terms of internal covariate shift has repeatedly surfaced in debates in the technical literature and broader discourse about how to present machine learning research. In a memorable speech given while accepting a Test of Time Award at the 2017 NeurIPS conference, Ali Rahimi used internal covariate shift as a focal point in an argument likening the modern practice of deep learning to alchemy. Subsequently, the example was revisited in detail in a position paper outlining troubling trends in machine learning [Lipton & Steinhardt, 2018]. In the technical literature other authors ([Santurkar et al., 2018]) have proposed alternative explanations for the success of BN, some claiming that BN’s success comes despite exhibiting behavior that is in some ways opposite to those claimed in the original paper.
We note that the internal covariate shift is no more worthy of criticism than any of thousands of similarly vague claims made every year in the technical ML literature. Likely, its resonance as a focal point of these debates owes to its broad recognizability to the target audience. Batch normalization has proven an indispensable method, applied in nearly all deployed image classifiers, earning the paper that introduced the technique tens of thousands of citations.
7.5.7. Summary¶
During model training, batch normalization continuously adjusts the intermediate output of the neural network by utilizing the mean and standard deviation of the minibatch, so that the values of the intermediate output in each layer throughout the neural network are more stable.
The batch normalization methods for fully connected layers and convolutional layers are slightly different.
Like a dropout layer, batch normalization layers have different computation results in training mode and prediction mode.
Batch Normalization has many beneficial side effects, primarily that of regularization. On the other hand, the original motivation of reducing covariate shift seems not to be a valid explanation.
7.5.8. Exercises¶
Can we remove the fully connected affine transformation before the batch normalization or the bias parameter in convolution computation?
Find an equivalent transformation that applies prior to the fully connected layer.
Is this reformulation effective. Why (not)?
Compare the learning rates for LeNet with and without batch normalization.
Plot the decrease in training and test error.
What about the region of convergence? How large can you make the learning rate?
Do we need Batch Normalization in every layer? Experiment with it?
Can you replace Dropout by Batch Normalization? How does the behavior change?
Fix the coefficients
betaandgamma, and observe and analyze the results.Review the online documentation for
BatchNormto see the other applications for Batch Normalization.Research ideas: think of other normalization transforms that you can apply? Can you apply the probability integral transform? How about a full rank covariance estimate?